Feature Engineering#
Import des outils / jeu de données#
1import pandas as pd
2import seaborn as sns
3
4from src.config import data_folder
5from src.utils import init_notebook
1init_notebook()
1df = pd.read_csv(
2 f"{data_folder}/data-cleaned.csv", sep=",", index_col="ID", parse_dates=True
3)
1df.head()
| Year_Birth | Education | Marital_Status | Income | Kidhome | Teenhome | Dt_Customer | Recency | MntWines | MntFruits | ... | NumWebPurchases | NumCatalogPurchases | NumStorePurchases | NumWebVisitsMonth | AcceptedCmp3 | AcceptedCmp4 | AcceptedCmp5 | AcceptedCmp1 | AcceptedCmp2 | Response | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | |||||||||||||||||||||
| 5524 | 1957 | Graduation | Single | 58138.0 | 0 | 0 | 2012-09-04 | 58 | 635 | 88 | ... | 8 | 10 | 4 | 7 | 0 | 0 | 0 | 0 | 0 | 1 |
| 2174 | 1954 | Graduation | Single | 46344.0 | 1 | 1 | 2014-03-08 | 38 | 11 | 1 | ... | 1 | 1 | 2 | 5 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4141 | 1965 | Graduation | Together | 71613.0 | 0 | 0 | 2013-08-21 | 26 | 426 | 49 | ... | 8 | 2 | 10 | 4 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6182 | 1984 | Graduation | Together | 26646.0 | 1 | 0 | 2014-02-10 | 26 | 11 | 4 | ... | 2 | 0 | 4 | 6 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5324 | 1981 | PhD | Married | 58293.0 | 1 | 0 | 2014-01-19 | 94 | 173 | 43 | ... | 5 | 3 | 6 | 5 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 25 columns
Création de variables#
Tableau. Variables ajoutées
| :— | :— | | NbAcceptedCampaigns | Nombre de campagnes marketing acceptées (hors variable cible) | | HasAcceptedCampaigns | Le client a déjà accepté une campagne (1) ou non (0) | | NbChildren | Nombre d’enfants au total (bas âge + adolescent) |
1## todo : faire une var somme des achats sur le web
2## todo : faire un client type par type d'achat (web / magasin) => est-ce que les gens qui achètent en web / magasin sont différents ?
3## todo : créer une variable duréeClient qui dit depuis quand le client est inscrit
1## todo: commenter la démarche
1df["NbAcceptedCampaigns"] = 0
2
3for i in range(1, 6):
4 df["NbAcceptedCampaigns"] += df[f"AcceptedCmp{i}"].astype(int)
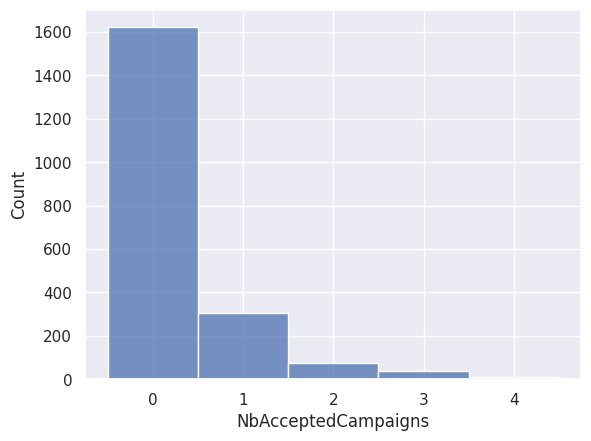
1sns.histplot(df["NbAcceptedCampaigns"], discrete=True)
<Axes: xlabel='NbAcceptedCampaigns', ylabel='Count'>
1df["HasAcceptedCampaigns"] = df["NbAcceptedCampaigns"] > 0
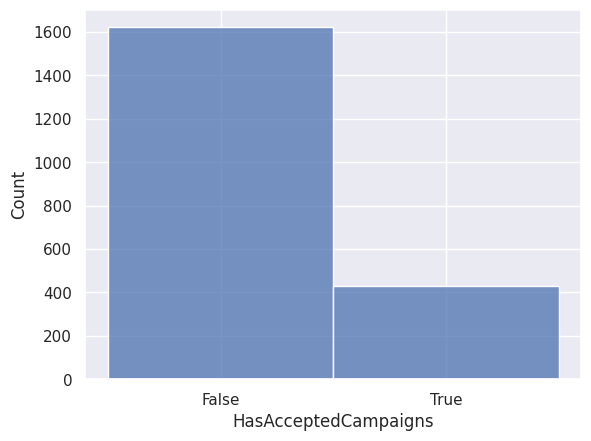
1sns.histplot(df["HasAcceptedCampaigns"].astype(str))
<Axes: xlabel='HasAcceptedCampaigns', ylabel='Count'>
1df_clients = df[df["HasAcceptedCampaigns"]]
2df_not_clients = df[~df["HasAcceptedCampaigns"]]
1## todo: vérifier si par exemple Kids et Teen apportent des informations différentes => si les deux sont complémentaires, on les laisse / sinon on les supprime au profit de notre nouvelle variable
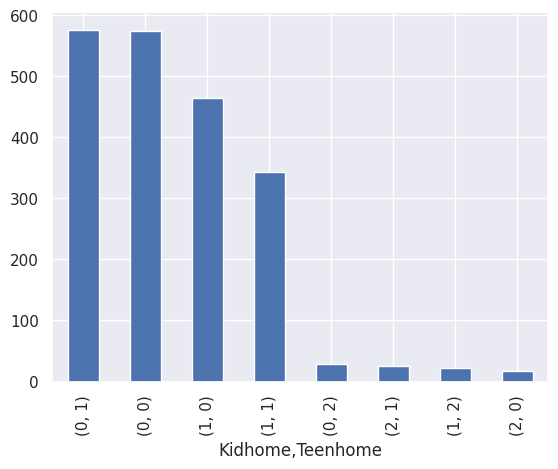
1df[["Kidhome", "Teenhome"]].value_counts().plot(kind="bar")
<Axes: xlabel='Kidhome,Teenhome'>
1df["NbChildren"] = df["Kidhome"].astype(int) + df["Teenhome"].astype(int)
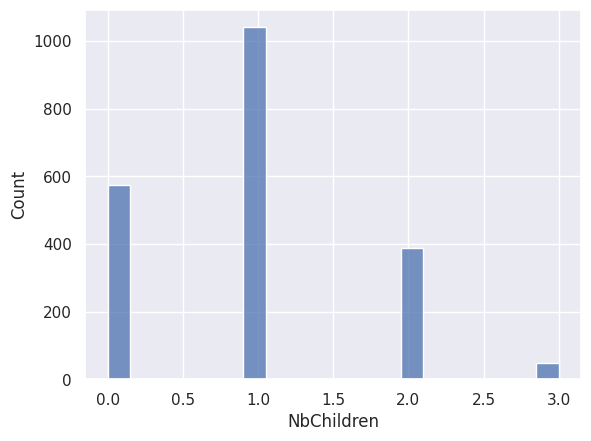
1sns.histplot(df["NbChildren"])
<Axes: xlabel='NbChildren', ylabel='Count'>
1## todo: créer une variable "NbAcceptedCampaignsWithResponse", qui contient donc la 6ème campagne marketing => l'objectif est de clusteriser les gens en fonction de "à quel point ils sont marketables" => c'est-à-dire, on présente nos résultats en disant sur qui il vaut mieux se concentrer pour faire des pubs
1## todo: créer une variable "RevenuePerClient" => le revenu rapporté par chaque client => ce serait plutôt juste une variable type "KPI" à afficher dans un dashboard non ?
1## todo: de même, créer une variable "RevenueWinePerClient" => le revenu de vin pour chaque client, et faire de même pour chaque produit => par la suite on pourra faire des représentations "quel client rapporte le plus de vin"
Sauvegarde du Dataframe#
1df.to_csv(f"{data_folder}/data-cleaned-feature-engineering.csv")