Analyse exploratoire#
Import des outils / jeu de données#
1import matplotlib.pyplot as plt
2import pandas as pd
3import seaborn as sns
4
5from src.utils import init_notebook
1init_notebook()
1df = pd.read_csv(
2 "data/kickstarter_1.csv",
3 parse_dates=True,
4)
Présentation#
Plan de la présentation
1) Introduction
présentation du jeu de données
modélisation sous forme d’analyse de survie
définition de la problématique
2) Estimation univariée
Non-paramétrique
Paramétrique
3) Régression multivariée
Non-paramétrique
Paramétrique
Machine Learning
4) Conclusion
réponse à la problématique
Jeu de données#
Le jeu de données contient une liste de 18 143 projets Kickstarter menés entre le 15 décembre 2013 et le 15 juin 2014.
Pour chaque projet, nous disposons notamment de :
quand son objectif a été atteint:
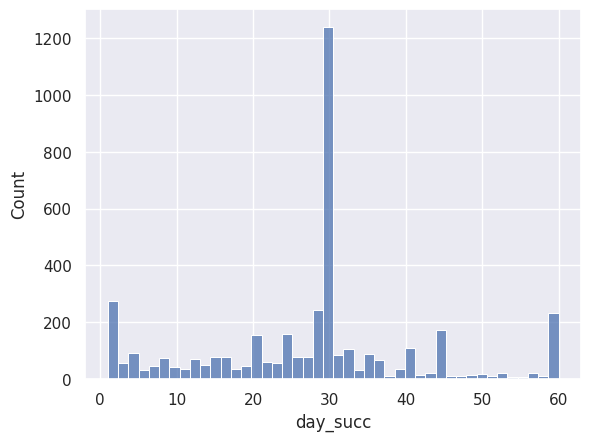
day_succsi l’objectif a été atteint:
Statussi le projet dispose d’une vidéo promotionnelle :
has_videol’objectif financier:
goalsi le projet a un compte facebook:
facebook_connectedle nombre de followers du projet:
facebook_friendsle nombre de financeurs:
backersla catégorie du projet (art, cuisine, technologie, …):
catetc.
Il est important de préciser que le jeu de données a été mis à l’échelle pour les variables quantitatives (scaling), d’où des valeurs décimales pour des variables entières.
Modélisation#
\(T\) : variable aléatoire modélisant la date de financement (succès du projet).
fonction de survie \(P(T > t)\) : probabilité que le projet n’ait pas encore été financé au temps \(t\)
censure (à droite) : les projets n’ont pas été financé dans le temps imparti (mais auraient pu être financés s’ils avaient eu plus de temps)
Présentation des variables#
1print(
2 f"Il y a {df.shape[1]} variables "
3 f"qui décrivent {df.shape[0]} projets kickstarter."
4)
Il y a 56 variables qui décrivent 4175 projets kickstarter.
1# df.info()
Nous séparons les variables numériques des variables catégoriques pour plus de commodités.
1var_categoriques = (
2 [f"cat{i}" for i in range(1, 16)]
3 + [f"curr{i}" for i in range(1, 7)]
4 + ["Status", "facebook_connected", "has_video"]
5)
1var_numeriques = df.columns
Nous convertissons les variables catégoriques en type category. (Nous les convertissons au préalable en type string car cela facilite l’affichage de la légende avec Matplotlib et Seaborn)
1df[var_categoriques] = df[var_categoriques].astype(str).astype("category")
Nous convertissons les variables au format date.
Nous avons 11 variables catégoriques, 16 variables quantitatives (dont 15 entières) ainsi qu’une variable de type date.
Visualisations#
1sns.histplot(df["day_succ"])
<Axes: xlabel='day_succ', ylabel='Count'>
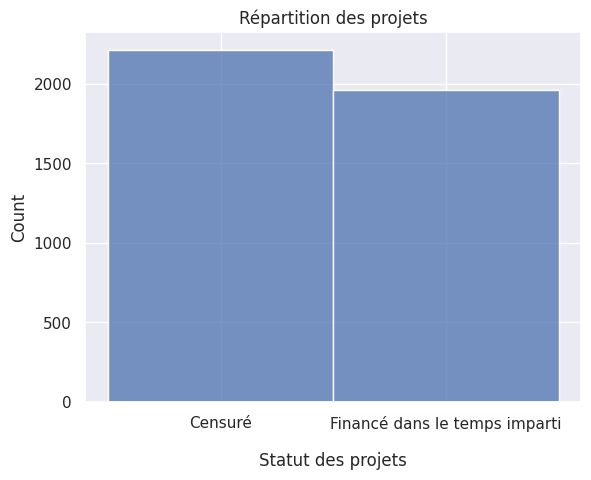
1plt.title("Répartition des projets")
2
3sns.histplot(df["Status"])
4
5plt.xticks([0, 1], ["Censuré", "Financé dans le temps imparti"])
6plt.xlabel("Statut des projets", labelpad=15) # labelpad add vertical space
Text(0.5, 0, 'Statut des projets')
Problématique#
Voici les deux questions qui guident notre projet :
1) Peut-on prédire si un projet sera financé ? À quelle date ?
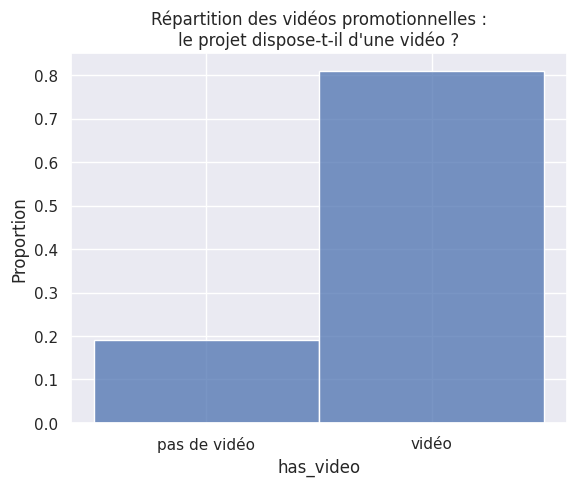
2) Quel est l’impact d’une vidéo promotionnelle sur le succès d’un projet ?
1plt.title(
2 "Répartition des vidéos promotionnelles :\nle projet dispose-t-il d'une vidéo ?"
3)
4
5sns.histplot(df["has_video"], stat="proportion")
6
7plt.xticks([0, 1], ["pas de vidéo", "vidéo"])
8plt.show()
1# old problematic # Dans une première **analyse univariée**, nous chercherons à **modéliser la fonction de survie du financement d'un projet Kickstarter**, c'est-à-dire la probabilité que le projet n'ait pas encore été financé, en fonction de sa durée de vie, en jours. # # Dans une deuxième **analyse multivariée**, nous déterminerons **comment les différents paramètres des projets Kickstarter influencent-ils la durée nécessaire pour atteindre leur objectif** de financement ou leur échec dans le temps imparti ?